有道翻译支持哪些文件格式的翻译?
发布时间:2026-01-03
有道翻译支持多种常见文件格式的翻译,包括 PDF、Word(.doc/.docx)、PowerPoint(.ppt/.pptx)、文本文件(.txt)、Excel(.xls/.xlsx)等。用户可以直接上传这些文件进行整篇翻译,支持快速处理文档中的文字内容。
有道翻译支持的文本文档格式使用教程
文本文件格式概览与上传步骤
- 支持的文本格式: 在使用有道翻译进行文档翻译时,最基础也是最兼容的格式是纯文本文件,一般扩展名为
.txt。这类文件内部通常只包含纯文字内容,没有复杂的排版和样式,因此在上传到有道翻译之后,系统几乎可以做到“直接读取+直接翻译”,减少编码不兼容、字体缺失等问题。对于不少用户来说,把内容从其他软件复制出来,保存为 UTF-8 编码的 txt 文件,再交给有道翻译,是兼顾稳定与准确的做法。 - 上传文本的路径: 用户在电脑端使用有道网页翻译或有道文档翻译功能时,一般通过“上传文档”或“导入文件”的入口,将本地 txt 文件选择后上传。移动端 App 中则可以通过“文件翻译”或“文档翻译”模块,从手机存储或者云盘中选择相应 txt 文件。实际操作中,需要留意文件编码尽量使用 UTF-8 或常见的 GBK、GB2312 编码,避免特殊编码造成乱码。
文本文档翻译时的注意事项与小技巧
- 编码与语言识别: 文本文档翻译的关键在于编码正确与语言识别无误。若 txt 文件采用冷门编码格式,上传到有道翻译后有可能出现乱码情况,从而影响翻译结果。建议在编辑文本时统一存为 UTF-8 编码,尤其是中英混排、多语言混排的场景。此外,有道翻译通常会自动识别源语言,但如果内容语言较为接近或混杂,用户最好手动选择源语言,提升翻译准确度。
- 段落结构与格式保留: txt 文件没有复杂的排版,但换行、空行、段落划分依然会影响翻译效果。有道翻译在处理纯文本时,会根据换行和标点来拆分句子和段落,因此建议在撰写文本时保持清晰的逻辑分段。对于需要后续排版的内容,先用 txt 在有道翻译中完成初稿翻译,再复制到 Word、排版工具中进行格式美化,是一个兼顾效率与质量的工作流。
有道翻译支持的 Word 文档格式使用教程
支持的 Word 文件类型与适用场景
- 常见 Word 格式: 在日常办公中,
.doc和.docx是最常见的文字处理文件格式。有道翻译在文档翻译模块中通常直接支持这两种格式,能够识别文档中的正文、标题、部分表格以及编号列表内容。对于以文字为主、排版要求中等的文档,直接上传 Word 文件即可完成整篇翻译,这对于合同初稿、学术论文初稿、产品说明书等场景十分高效。 - 复杂排版的兼容性: 有道翻译在处理 Word 文档时,会尽量保持原有的段落结构和基本样式,尤其在 .docx 格式下兼容性更好。但对于包含大量图文混排、内嵌对象、脚注或批注的复杂文档,翻译后的格式可能出现偏移或样式简化。用户在使用这类文档翻译时,建议关注文本内容是否完整翻译,而将精细排版放到翻译完成后的人工编辑阶段。
Word 文档上传与翻译操作流程
- 有道翻译电脑端文档翻译入口: 在电脑浏览器中访问有道翻译或有道文档翻译页面时,一般可以看到“文档翻译”或“上传文档”的按钮。点击后选择本地的
.doc或.docx文件,确认源语言与目标语言,再发起翻译任务。有道会将文档上传至服务器,进行分段识别和机器翻译,稍后提供译文下载或在线查看。对于较大的 Word 文件,上传与处理时间也会相应延长,需耐心等待。 - 翻译结果的导出与校对: 翻译完成后,有道往往会提供下载译文文档的选项,格式通常与原文件保持一致,例如下载为
.docx。用户可以在本地打开译文,进行术语统一、语句润色、专业名词校对等操作。特别是在合同、报告、学术研究等场景中,机器翻译结果只是初稿参考,最终稿件应由熟悉专业领域的人员进行审核,以保证准确性与合规性。
有道翻译支持的 PDF 文档格式使用教程
PDF 文件类型与内容识别能力
- 可复制文本的 PDF: 有道翻译能够一定程度支持 PDF 文件的翻译,尤其是那些以可复制文本为主、没有过多扫描图片的 PDF。此类 PDF 通常是由 Word、PPT 或排版软件导出而成,文本层结构清晰,OCR 识别负担较小,系统可以直接读取其中的文字内容并进行翻译。在上传前,用户可以尝试用阅读器选中一段文字进行复制,以判断文件是否属于可复制文本类型。
- 扫描版或图片型 PDF: 如果 PDF 是由扫描件生成,或者每一页都是图片形式,那么有道在翻译时会依赖 OCR(光学字符识别)技术先识别文字,再进行翻译。此类文件的翻译质量与原始扫描清晰度、语言字体、排版复杂度密切相关。清晰的打印体文字识别率相对较高,而模糊、歪斜、手写或复杂字体则会增加识别难度,导致翻译结果中出现错字或漏译,需要用户之后进行人工修正。
PDF 文档翻译的实用步骤与优化建议
- 上传路径与限制: 用户在使用 PDF 翻译时,一般同样通过有道的“文档翻译”功能入口上传文件。有的产品会对单个 PDF 的大小、页数有一定限制,如超过若干 MB 或若干页可能无法一次性翻译,需拆分文件或压缩后分批处理。上传前建议根据提示查看支持的文件大小上限,并尽量用压缩工具或拆分软件将文件控制在合理范围之内。
- 提升翻译质量的方法: 为提高 PDF 翻译效果,可优先使用源文件导出 PDF 的方式,保证文本层存在且结构清晰。如果只能使用扫描版,尽可能保证扫描分辨率适中、页面无严重倾斜,文字与背景对比度明显。此外,如果 PDF 中存在部分特殊术语或专业名词,可以在得到初译后手动批量替换或自行校对,将翻译结果与行业标准或权威资料对比,使最终译文既准确又符合专业惯例。

有道翻译支持的 PPT/Excel 等办公文件格式使用教程
PPT 文件翻译特点与适用情况
- 支持的演示文稿格式: 有道翻译通常支持
.ppt和.pptx格式的演示文稿文件,适合处理产品路演、课程课件、会议汇报等文档。系统会识别幻灯片中文本框里的内容,包括标题、正文、项目符号、图表中的部分文字等,并尝试在保持页面结构的前提下生成对应的译文文件。对于多语言展示或需要快速本地化的课件资料,这种方式能显著节省手工翻译时间。 - 复杂动画与嵌入内容: 需要注意的是,PPT 中的动画效果、过渡特效、视频、音频以及某些嵌入对象(例如外部图表控件)在翻译过程中通常不会被修改,只是保留原始形式。若文字以图片形式嵌入幻灯片中,系统可能无法直接识别或需要 OCR 处理。因此在制作需要翻译的演示文稿时,尽量将要翻译的内容以标准文本框方式呈现,减少图片文字,避免翻译后还要大量手动修改。
Excel 文件翻译与表格内容处理技巧
- 支持的表格文件格式: 在表格类文件中,有道翻译对
.xls和.xlsx文件有基本支持。表格中的单元格文本会被识别并进行翻译,在某些情况下还能保留原有单元格结构。此类功能适用于产品清单、价格表、数据说明表、对照表等文件,尤其适合需要将大量短句、短语快速转换成另一种语言的场景。对于含有多工作表的复杂 Excel 文件,翻译时一般会逐个工作表处理。 - 数值与公式的保护: 在翻译 Excel 表格时,有道系统通常只会处理文本内容,不会刻意修改数值、货币、日期格式或公式,以避免破坏原始数据逻辑。用户在上传前可大致排查表格,确保那些不应被翻译的字段使用统一格式或标记,翻译完成后再进行逐项检查。如果发现某些专业术语或缩写被误译,可在译文中通过查找替换迅速校正,保持不同工作表之间术语的一致性,避免出现同一字段多种译法的情况。
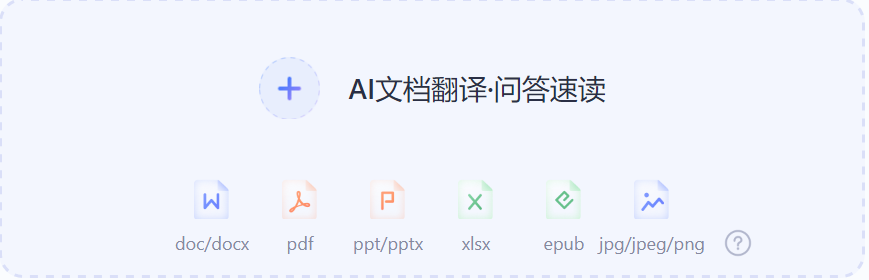
有道翻译支持的图片/网页/其他内容格式使用教程
图片与截图文字翻译的可用形式
- 图片识别翻译: 虽然严格意义上讲,图片并非传统“文档”格式,但有道翻译旗下的 App 和部分工具通常支持图片文字识别翻译。用户可以通过手机拍照或上传本地图片(如
.jpg、.png等),让系统借助 OCR 技术识别图片中的文字,再给出翻译结果。这种方式特别适合翻译菜单、路牌、教材截图、PPT 截图等非结构化内容,为外出旅行或课堂学习提供即时辅助。 - 图片翻译的局限性: 在图片翻译过程中,文字的字体、大小、背景颜色、对比度都会影响识别准确度。如果图片过于模糊、被遮挡、倾斜严重,或者使用艺术字体,识别效果可能明显下降,从而导致翻译错误。为了提升翻译质量,用户应尽量提供清晰度较高、光线均衡的图片,并避免将关键文字置于花纹复杂或颜色接近的背景之上,在必要时通过编辑工具先裁剪、增强对比度后再上传。
网页内容与其他文本入口的应用方法
- 网页文本与链接: 部分有道产品形态允许用户直接粘贴网页链接或整段网页文本进行翻译。虽然这不属于“文件上传”范畴,但在功能体验上接近于对 HTML 内容的文本层翻译。系统会提取可见文本并给出译文,适用于阅读外文新闻、技术博客、论坛帖子等内容。对于结构复杂、脚本较多的网页,翻译工具可能无法覆盖全部动态生成的文字,用户可以通过手动复制页面中关键段落来弥补。
- 其他支持与拓展形式: 除了传统文件和网页,一些有道相关产品还支持聊天窗口、笔记、云文档中的内容直接调用翻译接口。例如在有道云笔记、有道云协作或浏览器扩展中,选中部分文本即可弹出翻译窗。这些并不以“文件格式”区分,但本质上仍然围绕文本内容进行处理。理解这一点有助于用户根据实际工作流,灵活选择最适合自己的翻译入口,提高整体使用效率。
常见问题(FAQ)
有道翻译是否支持所有版本的 Word、PPT、Excel 文件?
只要最终保存为常规的 .doc、.docx、.ppt、.pptx、.xls、.xlsx 等主流格式,一般都能被有道翻译识别和处理。
扫描 PDF 的翻译效果和可编辑 PDF 有什么差别?
扫描 PDF 是以图片为主,有道翻译需要先用 OCR 把图片中的文字“看出来”,再进行翻译,因此会受到图像清晰度、字体和排版的限制。可编辑 PDF 则通常包含可直接复制的文字层,系统可以更准确地识别句子与段落。
有道翻译能否直接翻译图片中的表格或流程图?
对于图片中的表格和流程图,有道翻译主要依赖 OCR 提取文字元素,而对表格线条、图形箭头等图形结构并不会智能重建。因此,用户通常只能获得文字内容的译文,而难以直接生成带有结构的可编辑表格或流程图。




